

Originally a video game, Lunar Lander provides an interesting control problem for engineers and a benchmark for AI algorithms. The goal is to optimize the rocket's trajectory and find the best way to navigate a rocket from its starting point to a landing pad.
The full flight mission succeeds when you land the craft safely between the flags, using as little fuel as possible. Instead of trying to learn autonomy for an entire complex task all at once, we divide the flight task into three separate skills.
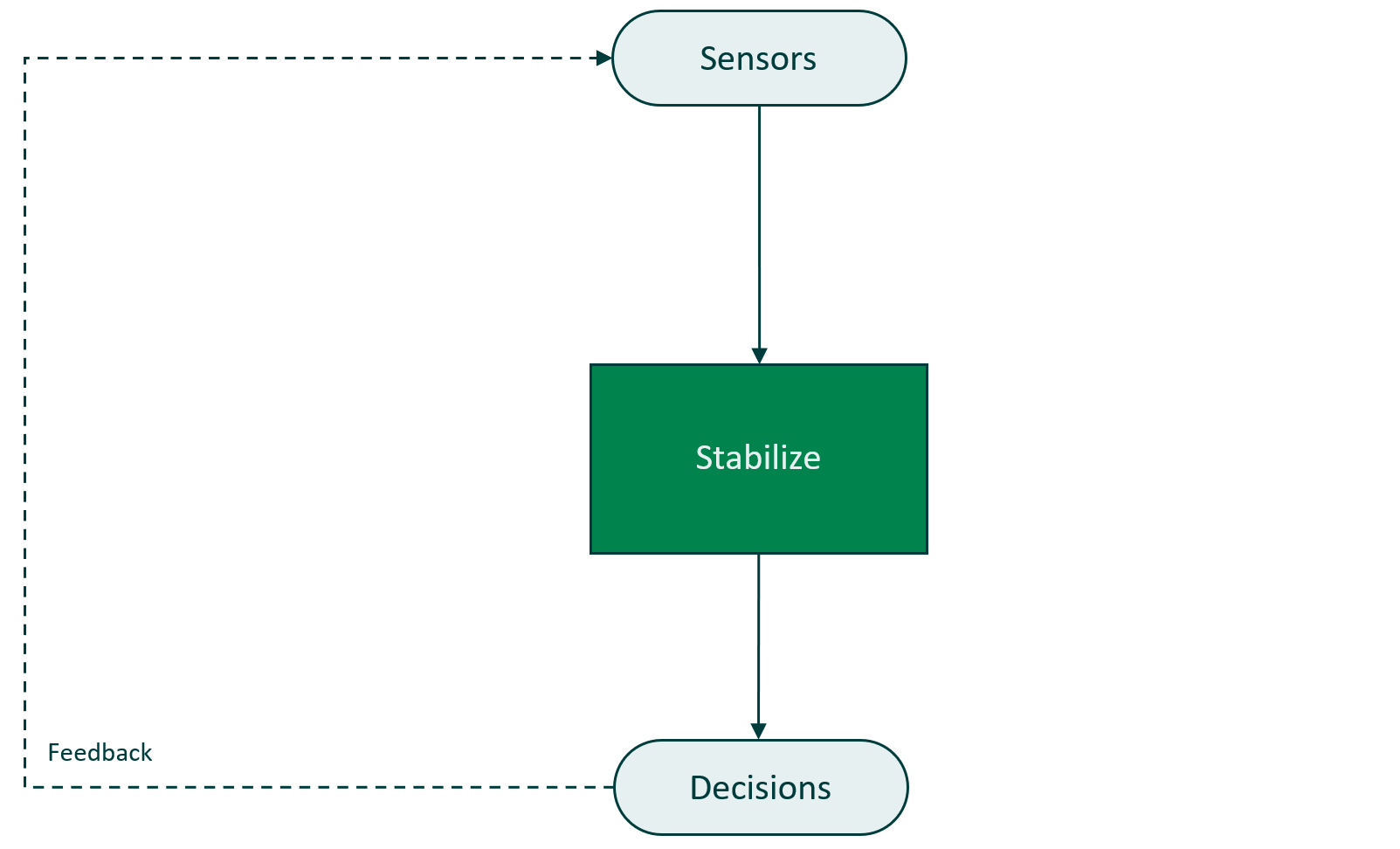
A complete agent should be able to stabilize, orient over the landing zone, and land. Let's train our first agent to learn the stabilize skill only.
As you can see above in the video, a competent stabilize skill will hover the craft.
Establishing an Environment where the Agent can Practice and get Feedback
The Python Gymnasium package provides a simulator that runs the flight scenario virtually to view the latest state of the environment and take actions to be able to land the craft.
Gymnasium is a Python package providing Python simulation environments, where we can try to most optimally solve a given solution with increasing complexity.
Gymnasium provides an:
- environment: given by an observation space, an environment depicts on what it "sees". In certain simulators this could be a (x, y) position, in others it might be a full RGB picture.
- interface for actions: the actions an agent can take on the environment (e.g., steer left, steer right)
Getting feedback about the actions of the agent is important, but that alone won't help an agent perform this flight control mission.
To teach this agent flight stability we can use the Composabl platform SDK to create an agent, define scenarios, build skills, and train the agent stable flight control!
Creating an Autonomous Agent
Let's get started on implementing this agent! First, we need to install the Composabl SDK. For that, simply run the command:
pip install composablNow that our SDK is installed, we need to integrate the Gymnasium environment into the Composabl Simulator Specification. Luckily for us, Composabl comes with a lot of simulators out of the box, with Gymnasium being one of them.
The Composabl Python library provides modules for managing agents, skills, and scenarios.
from composabl.agent import Agent, Skill, ScenarioNext, you will need to configure the settings for your agent. The env key contains the name of your simulation environment, your compute target, and the pointer to your simulation environment. Let's run this agent training on our local machine, but Composabl also allows on-premises training in containers and training on Azure Kubernetes clusters.
config = {
"env": {
"name": "lunar_lander_sim",
"compute": "local"
"config": {
"address": "localhost:1337",
}
},
"license": <LICENSE_KEY>,
"training": {}
}Finally, create your agent with the Agent() method call.
agent = Agent(config)Creating Training Scenarios
Create scenarios that you will train your agent against. To train an agent to stabilize well across many conditions, we'll need scenarios where the craft is unstable (at a steep angle) and where the craft is stable (shallow or zero angle). We'll also need to train at different speeds, horizontal, and vertical positions.
stabilize_scenarios = [
{
"angle": 0,
"horizontal_position": [-0.2, 0.2],
"vertical_position": [-0.5, -0.5],
"velocity": [-0.2, 0.2],
},
{
"angle": -.17,
"horizontal_position": [-0.5, 0.5],
"vertical_position": [-0.5, -0.25],
"velocity": 0
},
{
"angle": 0.12,
"horizontal_position": [-0.7, 0.7],
"vertical_position": [-.65, -0.1],
"velocity": 0
}
]Defining Skills
In order to learn this skill, we need to define a reward function that quantitatively measures stability. The stabilize skill keeps the craft stable. It minimizes the angle the craft is tilted in either direction.
def stabilize_reward():
if {{{prev_state}}} is None:
reward = 0
VIEWPORT_W = 600
VIEWPORT_H = 400
SCALE = 30.0
reward = 0
# has the angle moved closer to 0?
if abs({{prev_state[4]}}) >= abs({{state[4]}}) + 0.1 * 180 / math.pi:
reward += 1
# has the x position remained stable?
if abs({{prev_state[0]}} - {{state[0]}}) <= 0.01 * (VIEWPORT_W / SCALE / 2):
reward += 1
else:
reward -= 1
# has the y position remained stable?
if abs({{prev_state[1]}} - {{state[1]}}) <= 0.01 * (VIEWPORT_W / SCALE / 2):
reward += 1
else:
reward -= 1Now we can define the stabilize skill.
stabilize_skill = Skill.remote("stabilize", stabilize_reward(), trainable=True)Then, add the training scenarios to your skill.
for scenario_dict in stabilize_scenarios:
scenario = Scenario(scenario_dict)
stabilize_skill.add_scenario(scenario)Next, add the skill to your agent.
agent.add_skill(stabilize_skill)Training the Agent
Now we can train the agent.
agent.train(train_iters=5000)In the background the Composabl SDK creates a training job, manages the training of the skill, outputs data on the behavior of the agent, and creates an AI model.